Bernice's Dev Bootcamp Blog ^_^
git, GitHub, and version control
October 5, 2015, Monday
This topic of version control has probably been talked about to death by everyone plus their mothers. But only because it's a really important concept. It cannot be emphasized enough!
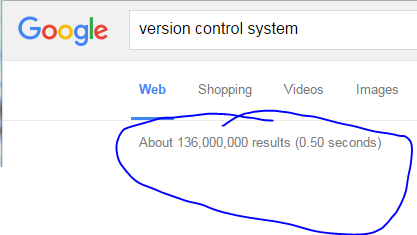
What are the benefits of version control?
Have you ever played those videogames that only have one save slot, and it auto-saves in such a way that you've made the game accidentally unwinnable? (For example, autosaving right after you've accidentally destroyed or lost some plot-advancing item (Diablo 2), or even auto-saving right after your army is dwindled and your important general was killed (Total War), or even realized that some tactical decision you made several turns ago has turned out to be a strategical error and now all the other factions have ganged up against you (Civilization and Total War), or auto-saving right when you've glitched into a wall (Dying Light), or auto-saving when the enemies are right beside you so they kill you instantly as soon as you load the game. Oh great, now you have to start over again from the beginning.
(Yes, I play too many videogames, and in general I dislike games that auto-save and don't allow you multiple save slots. But that's another story for another day).)
Have you ever accidentally saved over your work, but then realized that you've deleted something really important, and you can't remember how to put it back?

What is "version control"? One of my friends so succinctly says:
"They are tools to help you AVOID massive fuckups ;-)"A good way to think about version control is: it is like a videogame with multiple save slots, so if you've accidentally lost that plot-advancing item, or you've made some strategic decisions that gave you a bad outcome, you can just go back to that known good saved state, and you don't need to start the game from the beginning.
Or, if you don't play videogames, you've performed a backup of your entire OS each time right before installing some new software, and you keep each version of the old backups. One day, you've suddenly discovered that the new driver or whatever is incompatible with everything else, or the new software is actually malware that corrupted your system. You can just revert to a recent backed-up state. If you find that this does not solve your problem, you revert backwards through each iteration until you find the backup with a known good state. This way, you don't have to re-install your OS or figure out which software or driver is incompatible with what.
If those examples are still not relatable enough, here's an example that more people might have encountered.

Let's consider that you have crafted this awesomely complicated Excel spreadsheet (let's call this myExcelv1.xlsx). Everything works properly. One day, you needed to change some formulae for whatever reason, but you are not sure if the change that you've made will mess up the other calculations and references.
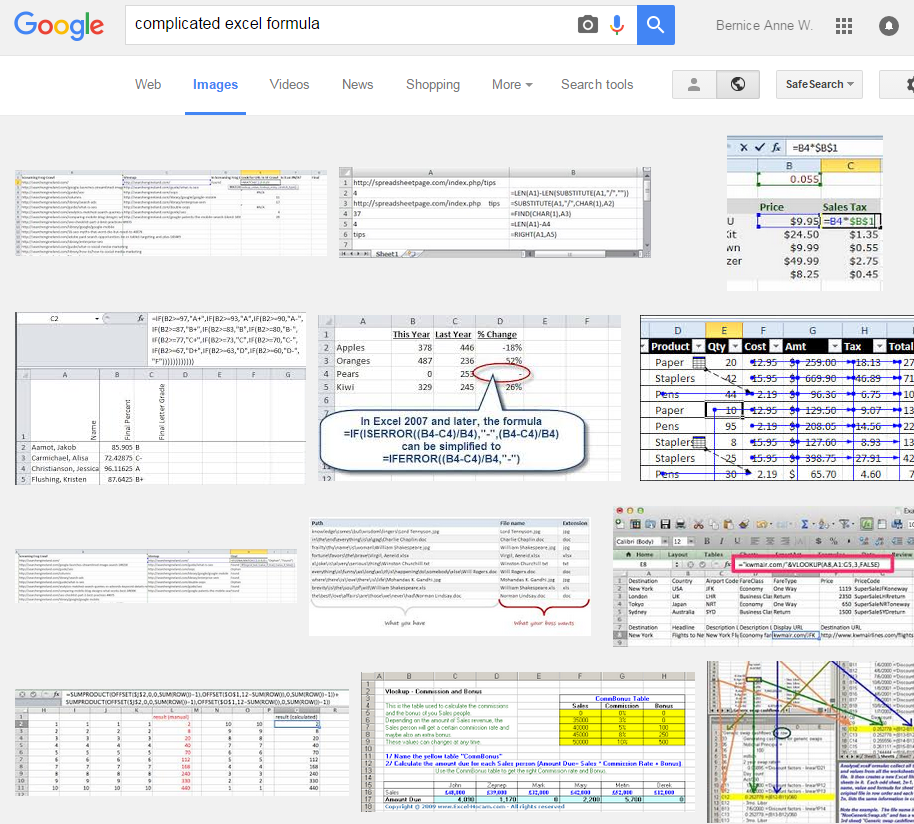
In summary "version control" is the idea. "Version control system" is the implementation of this practice, but nowadays it is more commonly the software system that implements the practice of controlling versions.
git is just one of the version control systems out there, the other being SVN or "SubVersion" or CVS (not the pharmacy). See here for a more comprehensive list: https://en.wikipedia.org/wiki/List_of_version_control_software. See here for a review of different version control systems: http://www.smashingmagazine.com/2008/09/the-top-7-open-source-version-control-systems/
How does git help you keep track of changes?
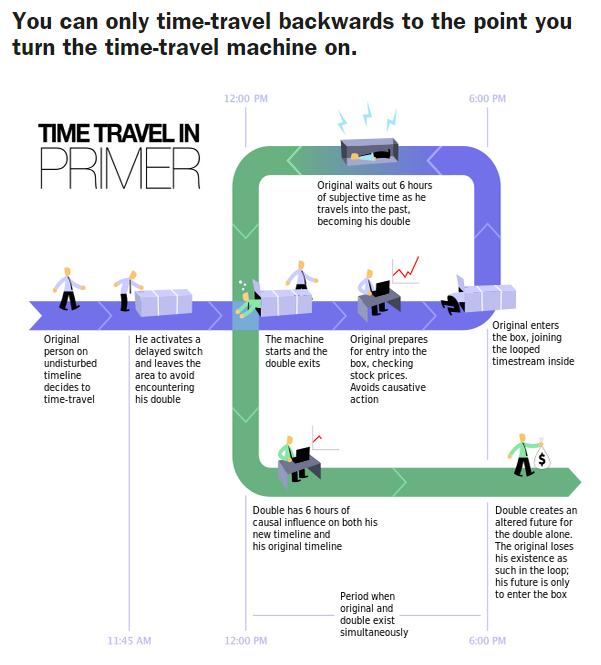
Basically, a version control system like git can be downloaded and installed on your local machine, and it can do all these wonderful things like tracking the changes. Since I'm using git, here's an example of my git log output to show the tracked changes:
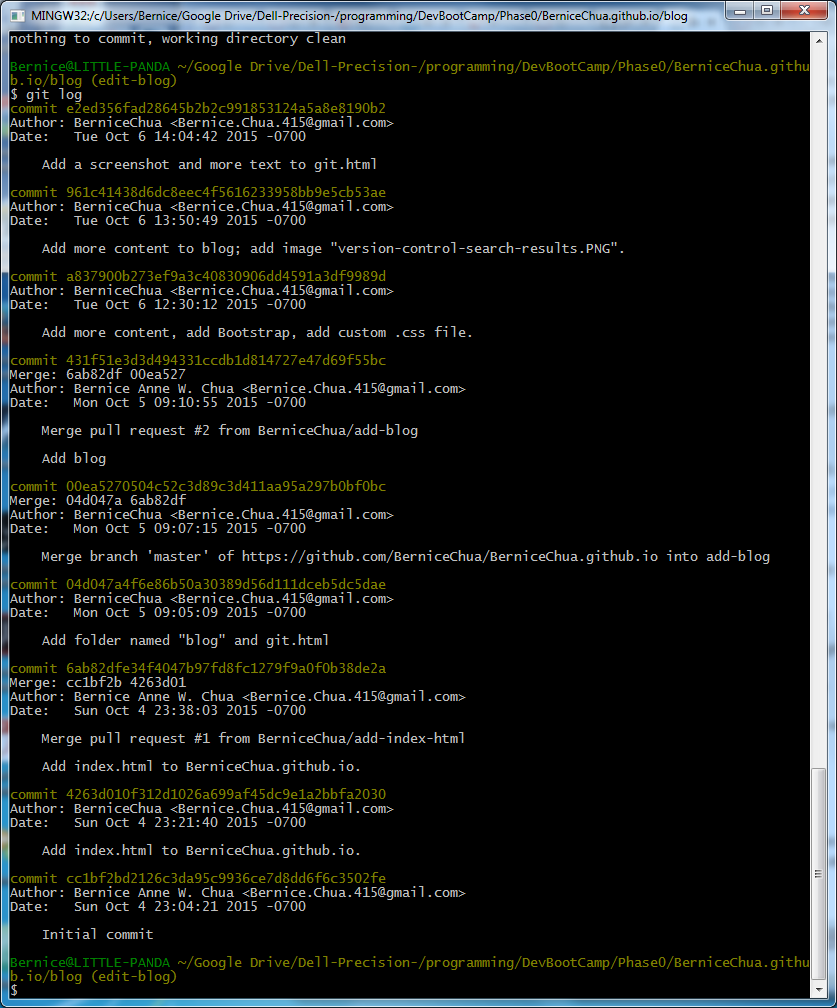
git log output. (I have a lot of commitments...)If you would like to try out git for yourself, you can download it from https://git-scm.com/downloads. Then follow the instructions for installing it.
There are also lots of useful guides found online:
- git FOR NON-DEVELOPERS!!!! :D (Now, non-developers have no excuse!!!)
- https://github.com/jlord/git-it (I actually used this one to learn git.)
- https://git-scm.com/doc
- https://git-scm.com/book/en/v2
- http://skillcrush.com/2013/02/20/get-started-working-with-git/
- https://www.youtube.com/watch?v=Y9XZQO1n_7c
- https://www.youtube.com/watch?v=r63f51ce84A
- https://www.codeschool.com/courses/git-real
- http://www.joelonsoftware.com/articles/fog0000000043.html
- http://www.freecodecamp.com/challenges/waypoint-save-your-code-revisions-forever-with-git
- https://www.udacity.com/wiki/ud775
- https://www.udacity.com/course/viewer#!/c-ud805/l-3666138591/m-643368749
- https://www.udacity.com/course/how-to-use-git-and-github--ud775
- https://www.codecademy.com/blog/74-getting-started-with-git
- Basically, just do a Google search or if you're a visual learner like me, you can find these guides in Youtube also.
Someone may argue, "But Bernice, regular MS Word and regular MS Excel and Photoshop already have these features inside their program. You can undo and redo actions. Why do I need to do all these?" To this, I say, "When you turn off those programs and save, then later turn them back on and realize that something is not right, you cannot access that 'history' and undo stuff." I am also a lazy person, so I don't want to do something if it has no beneficial effect to anyone at all. But in this case, a temporary and small inconvenience is worth it, if it prevents much wailing and gnashing of teeth later on.
Now, this worst-case scenario has happened, and you've saved and shut down your program. How do you revert to the previous commit? The instructions in https://git-scm.com/book/en/v2/Git-Basics-Undoing-Things shows us that
git commit --ammend can un-commit something for us.But what if you want to revert back to something a few commits ago? Like the question of this person in Stackoverflow: http://stackoverflow.com/questions/4114095/revert-to-a-previous-git-commit. In this case, we use
git revert and git reset. More details for each are here:git revert
- https://git-scm.com/docs/git-revert
- https://www.kernel.org/pub/software/scm/git/docs/git-revert.html
- http://schacon.github.io/git/git-revert.html
git reset

git log. To get a more detailed look at each commit information, it's git log -p. But both of these commands will show all the commits since the beginning. If you want to limit the number of things you want to view, it's git log -# (replace '#' with a number). You can even combine them!! Example, typing git log -p -3 will show the detailed log of the last 3 commits. More information here: http://git-scm.com/docs/git-log And just like that, your problems are fixed. Like magic.

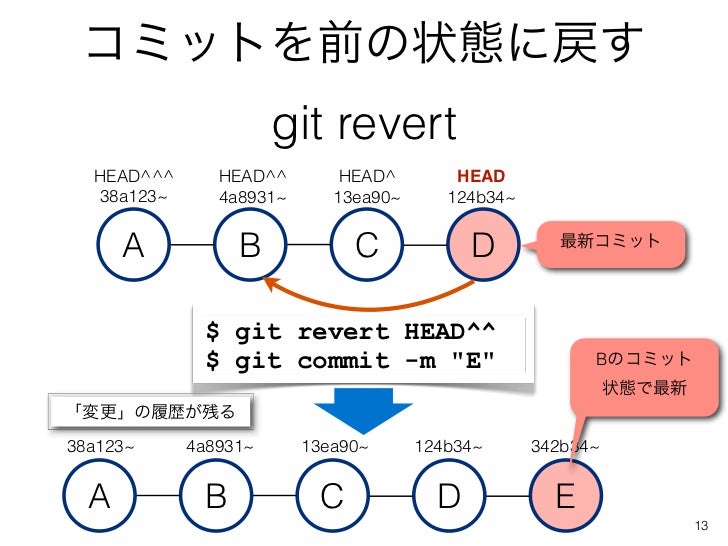
Image Source: http://www.slideshare.net/tamotsufuruya/git-14116631
Very important things to take note of:
- A commit is a recording of a snapshot of where your code is at a particular time. You can capture as many of these snapshots as you would like, and then you can go back and visit any snapshot whenever you would like.
- You cannot save what you did not
git addandgit commit. - About tracking changes: If a creator/git user does not
git addandgit commit -m 'Add comment here'early and often, git can only do so much to help you. Think of it like the videogame saves analogy. If you wait until much further in the game to save, then you decide that you want to restore to an earlier save point, that cannot happen if there's no early save point to go back to. - Adding messages to your commits are also important, so you will know which ones to look for later on in case you need to revert. Relying on the detailed view of
git log -pwill do no good if there were lots of changes and you're just greeted by a huge wall of text. - There is no penalty for committing multiple times. So
git add .like no one's watching;git commitlike there's no tomorrow!!
... instead of something like these:


Why use GitHub to store your code?
What is GitHub, then? Like the name implies, github.com is a website that is a hub where git repositories (the technical term for git 'information' is "repository") are stored. This is like an offsite/remote backup of your work. There are many other online repositories too, like BitBucket or Atlassian's Stash. But online repositories are more than offsite/remote/hosted storage. The true power of online repos (as they are abbreviated) is the ability for other people to see a project and collaborate on it AT THE SAME TIME, even though they are geographically apart.
Now, I'll tell you why this is super-useful -- even for non-coders. Let's go back to the example of the Excel file with tons of complicated formulae, and references to who-knows-where, which we called myExcelv1.xlsx.
The most likely natural habitat for such complex Excel files are usually in work environments. Someone who works on this file is more likely sharing this file with other people in a team, or from different teams, who are also working on the same file.
This is why online repos like GitHub are great tools for version control. Multiple people can work on something at the same time, even if they are all far apart from each other. And even if they work on something at the same time, they will not overwrite each other's work.

- Even if nothing else, it's a really good idea to store your work not only in your local machine. For example, something happens to your local machine for whatever reason, nobody will need to cry because all of that work is lost. (Because it's not, it's saved remotely.)
- If you want to work some more on your own code, you can fork a branch from the original, and mess with it as much as you want, without impunity!!!!!
- If other people collaborate with you, then they would also fork their own individual branches, and mess with the code to their heart's content. These collaborators don't even have to be in the same location as you.
- Because everyone is working on a branch of the code, the original known good working version remains intact.
- Eventually, people need to combine all the work back to the main branch (the
master). When this happens, this is called apull request. People can review each other's changes, and catch mistakes before combining the work back to the master. This makes collaborating in teams much easier.
How does this whole thing work?
There are many guides online, but here is a quick summary in git and GitHub, since those are the version controls that I'm currently using.
Instructions for creating a new repo:
- Step 1 - If you don't have this already, create a login and password in GitHub.
- Step 2 - In your own GitHub page, look for the "+" sign on the upper right corner beside your avatar/picture. You'll know you're in the right place because when you hover over it, a sign will appear that says "Create new...".
- Step 3 - Click on "+" sign on upper right corner beside your avatar/picture. A dropdown menu appears.
- Step 4 - On dropdown menu, please click "New repository". A new screen will appear.
- Step 5 - In this new screen, you can customize things about your repo such as the name. Please choose the name of your repo, choose whether or not the repo is public vs. private, and choose what kind of license is being used, since these are required fields. The others are optional, but you can add information on them if you want.
- Step 6 - When you have made sure that everything in Step 5 is to your liking, please click "Create Repository". Congratulations! You have made a repository in GitHub.
- Step 7 - In order to add more files to this repository, let us link it to your local machine through git. For this, please make sure that you have git installed from here: https://git-scm.com/downloads.
git config --global user.name "Your GitHub Username Here"git config --global user.email "your.email@address.com"
Instructions for forking an existing repo:
- Step 1 - If you don't have this already, create a login and password in GitHub.
- Step 2 - Please go to the GitHub page of whichever repo you'd wish to fork.
- Step 3 - On the upper right corner of the screen, under your avatar/picture, there is a button called "Fork". Please click on this.
- Step 4 - Congratulations! You have successfully forked a repo. You'll know that you have done this correctly if the name before the slash of the repo name is your own username, and under that, it says "forked from originalUser/source" or something like that, and the picture beside it is a branch instead of a book.
- Step 5 - In order to add more files to this repository, let us link it to your local machine through git. For this, please make sure that you have git installed from here: https://git-scm.com/downloads (Links to an external site.).
- Step 6 - On the right sidebar of the forked repo's page, there is a box under "HTTPS clone URL". Please click the box beside it that says "Copy to clipboard" when you hover over it.
- Step 7 - Please open your CLI. Please "cd" to the directory where you want to save your cloned git repos.
- Step 8 - Once you are in the directory that you want, please type this command:
git clone(and before hitting "Enter" on the keyboard, paste the URL that was copied in Step 6. NOW, hit Enter).- Congratulations! You now have a copy of this forked repo on your local machine.
Instructions for tracking changes:
git pull origin master(to make sure that you have the latest and greatest version of the project)git checkout -b [name_of_branch](to make sure that when you make a change gone awry, you can always revert to the original)git add [can be . or can be the filename(s)](prepares the changes to be committed)git commit -m "imperative message here"(saved state, prepares the changes to be pushed to the remote repository)git push origin [your-branch-name-here](pushes the changes to the remote repository)- It will ask for your username and password in the remote repo here.
- Then a message will appear with the details of what was pushed to the remote repo.
git checkout master(moves your view into the master branch)- either
git pull origin master, orgit fetch origin master(makes sure everything is up to date on your local repo AND the remote repo)
This happens in the remote repo; in this case in GitHub. Anyone who logs in and has access to the remote repo in GitHub will see this:

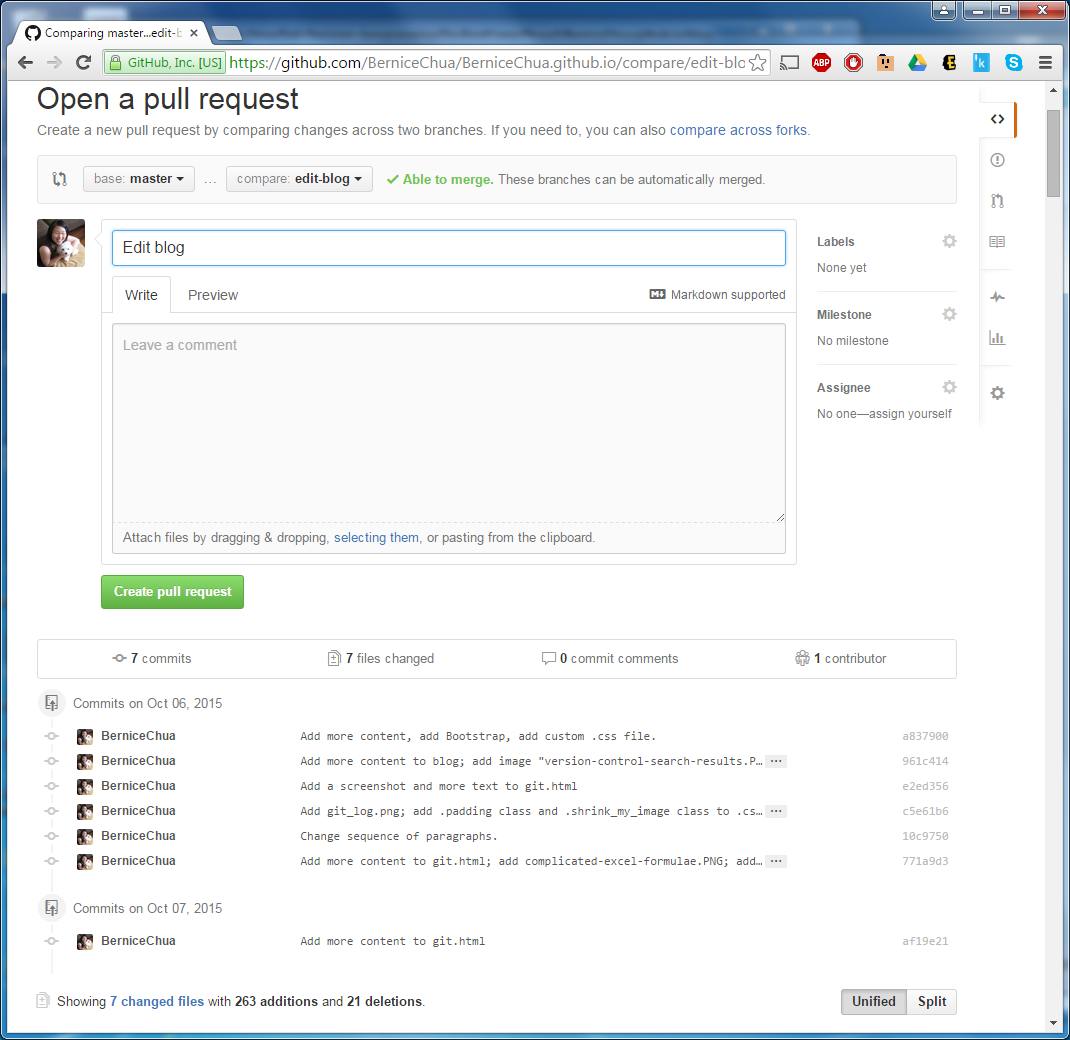
master branch. The person who submits the pull request can also compare the changes line by line, by scrolling down in that pull request page. Please take note the part that says "Able to merge. These branches can be automatically merged." When everything is completed, click "Create pull request", and wait for someone to review the pull request.In the next step, someone else typically reviews the pull request. They will see this screen:
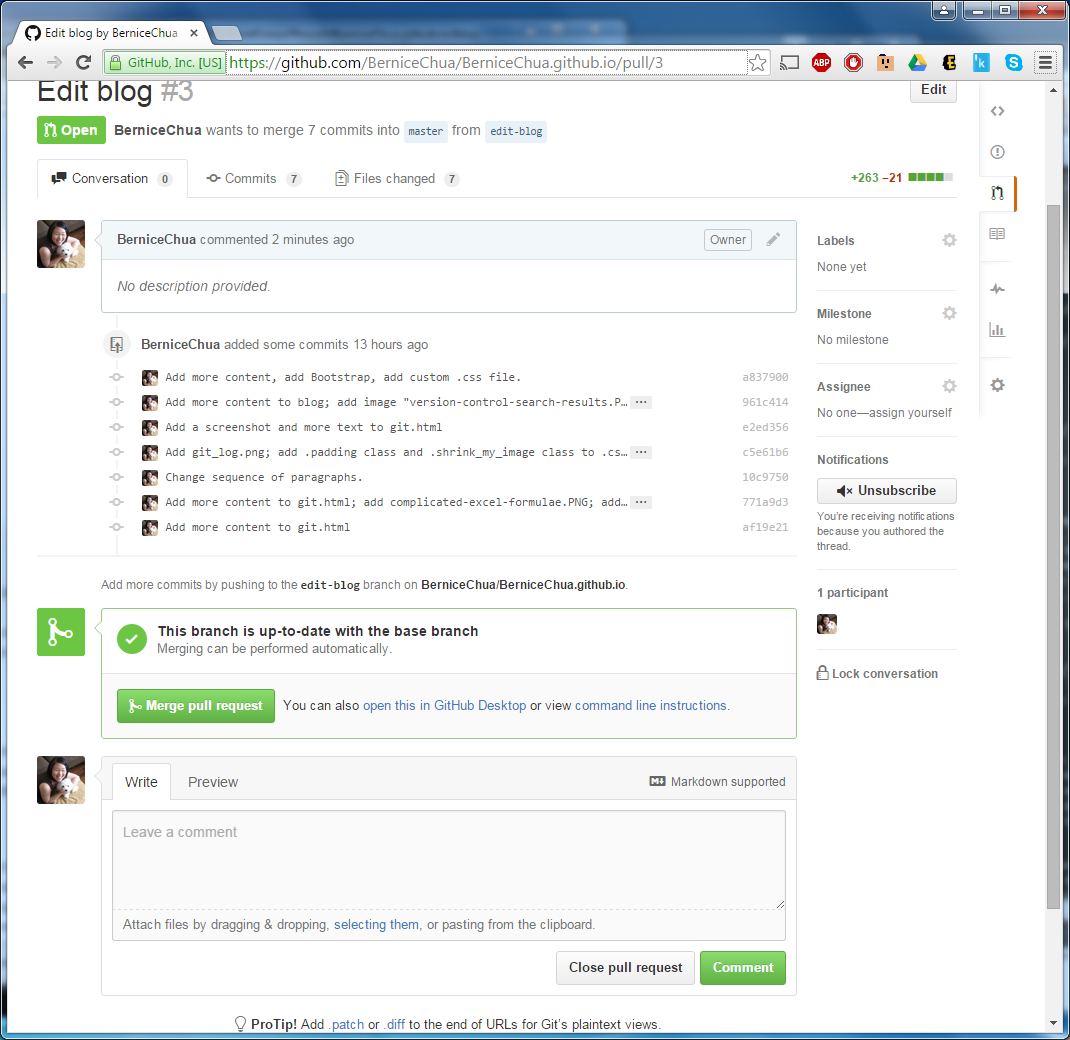
master branch. That's why it's very important to review the code and make sure that everything works properly before merging back!!Now, say it with me: git and GitHub are 2 very different things!
Despite the similarities in their names, git and GitHub are 2 different things. As mentioned earlier, git can be downloaded and installed in your computer, but GitHub cannot be, because it is the website (github.com). git is a system of version control, but there are many other systems too like CVS (again, still not the pharmacy) and SVN. GitHub is an online repository where people store their work, and other people can see this repo to collaborate on their work.Final Thoughts
I will be the first to admit that in the beginning, I was really scared of putting my work out there like that in GitHub for all to see. It was scary mainly because the work was still raw and not done yet. It was full of errors, and it looked really ugly to me. It's not done yet. It's incomplete. It's all over the place. It's not ready for other people to see. People will see how much I suck.", we tell ourselves. But let's face it: as people who create things, works will never be "done" or "completed". There will always be some kind of tweak that needs to happen, and as we mature and gain more experience and techniques, we'll always look back at our old work, and see what could have been done better. Hindsight is always 20x20, and past work will always suck compared to current work. (Hopefully.)Anyway, do you know about Brandon Sanderson? Now, this may seem like I'm changing the subject and it's coming out of nowhere, but bear with me and hear me out. Brandon Sanderson is a famous author who writes speculative fiction, specifically in the fantasy genre. He's one of my favorites because in his stories, the worlds are consistent and his writing style is elegant yet not overly flowery. I'd say he's a nice balance between Hemmingway/Walt Whitman/Asimov and Humberto Eco/Jose Luis Borges/Franz Kafka/Neal Stephenson. When people like us read their works, we think "Oh wow, they just made something automatically just like that." But truthfully, we don't see the process behind their writing -- the edits, re-edits, throwing away ideas that don't work with the rest even though it's a great idea by itself.
The point is, Brandon Sanderson wrote a book called Warbreaker. That's not surprising, since he's a writer. But what's different about this book is that he put everything online, including the original drafts, and all the edits. In his own words:
And so, I did something crazy. I went to Tor and asked if they’d be okay with me posting the entire version of Warbreaker AS I WROTE IT. Meaning, rough drafts. The early, early stuff which is filled with problems and errors. For those who are aspiring novelists, I wanted to show an early version of my work so they could follow its editing and progress.Think of what Brandon Sanderson could have done if he had version control or used GitHub! ^_^
The original essay in full context can be found here: http://brandonsanderson.com/books/warbreaker/warbreaker/, and you can download and read the different iterations of his book Warbreaker there too. He said a bunch of other things too, but the point that I was trying to make is that when I was reading the original drafts, I didn't really think that the writing was bad or problematic. It was good enough. I bet it's the same thing with our code. Regular people will not really think anything ill of it. Also, it's some kind of output rather than nothing, and it can always be fixed at a later iteration. The real reason why each of us is self-conscious of our own works is because we spend a lot of time with ourselves, so we know ourselves. But truthfully, other people don't know any better, and are being self-conscious of their own selves for the same reason that each of us is self-conscious of our own selves.
And when other smarter people pay attention to your code enough to want to fork a branch to fix stuff, that's actually a complement, because they think that it is worth their time to work on your code. So be happy!!! ^___^ (Speaking of which, wanna see my older repos? https://github.com/BerniceChua/BouncingDuckies and https://github.com/BerniceChua/Breakout_-_Java_Homework
So put your work out there, and happy coding!!! ^__^